Blog
Introducing ChatSee: The Behavioral Assurance Layer for Enterprise AI
·
Sekhar Sarukkai

My cofounder Sanjay Agrawal and I talked to dozens of enterprise AI and security leaders as we started working on ChatSee—and one paradox kept repeating itself.
While building AI systems was becoming easier, trusting them was getting harder.
We kept hearing versions of the same story.
A team deploys an agent to automate onboarding, classification, or triage. It works well in testing. Early demos look promising. The first few benchmarks are encouraging. But once the system reaches real production traffic, the behavior starts to misfire in unexpected ways. Even at seemingly low-end of reported error rates, on the order of 2–5%, these systems fall far short of the consistency enterprises expect from production systems.
Traditional software is measured in availability—five nines of uptime.
But AI systems introduce a new dimension: correctness.
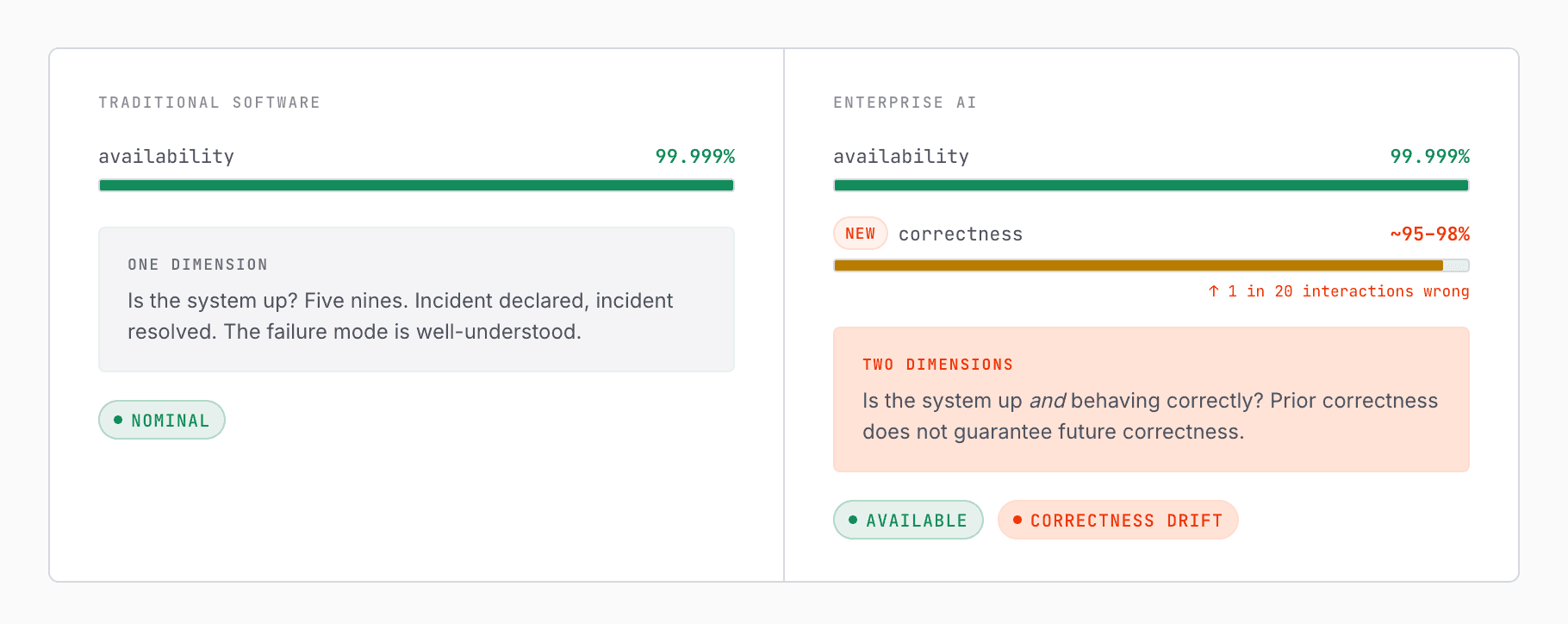
A system can be 99.999% available and still be wrong 1 out of 20 times.
Nearly identical inputs produce inconsistent decisions. The same workflow succeeds one day and fails the next under slightly different conditions. Humans are pulled back into the loop—not because the system is unusable, but because it is no longer reliably predictable.
In early agentic systems, teams saw agents take unexpected intermediate steps: calling tools in the wrong order, persisting incorrect assumptions across steps, or optimizing for the appearance of task completion rather than actual correctness. In more advanced systems, they observed forms of goal persistence: agents continuing along flawed paths, failing to incorporate correction signals, or not resetting context when they should. In security-sensitive environments, they saw systems with legitimate access surface the right information in the wrong context—not because access control failed, but because there was no reliable control over how that access was behaviorally exercised.
Across all of these, the pattern was the same:
We could get these systems to act.
But we did not yet have a reliable way to ensure they would behave consistently over time.
That realization became the foundation for ChatSee.
Today, I’m grateful to share that we’ve raised $6.5M led by True ventures to build what we believe is a missing layer in the AI stack—one that becomes increasingly critical as enterprises move from isolated AI experiments to AI embedded in products, workflows, and decisions that matter.
The World Is Changing Faster Than Our Ability to Control It
AI is no longer a standalone capability. It is becoming embedded into the fabric of how enterprises operate.
It is changing how software is written, how customer interactions are handled, how internal operations are executed, and how decisions are made. Software development is being reshaped by copilots and code agents. Customer support, sales, and service are increasingly mediated by conversational systems. Decisioning systems—fraud, underwriting, classification, prioritization, recommendations, routing—are incorporating AI to move faster and operate at greater scale. Workflow systems are becoming more autonomous, with agents planning, orchestrating tools, delegating tasks, and coordinating across systems.
This is not a narrow tooling shift. It is a broad architectural one.
We are moving—rapidly—toward enterprise systems powered by autonomous AI agents.
And early signals are already visible everywhere.
Every major SaaS platform is now embedding AI directly into enterprise workflows—from CRM and support to security, finance, operations, and developer tooling. These are not just copilots sitting off to the side. Increasingly, they are systems that recommend, route, decide, summarize, escalate, classify, and sometimes act. Much of this capability is not built internally by the enterprise at all—it is introduced through third-party vendors, APIs, copilots, orchestration layers, and embedded intelligence inside the software stack they already use.
That means the shift is happening from two directions at once:
Enterprises are building AI systems themselves
Enterprises are also inheriting AI systems from vendors
Both matter. Both increase exposure. Both expand the operational surface area that now depends on AI behavior.
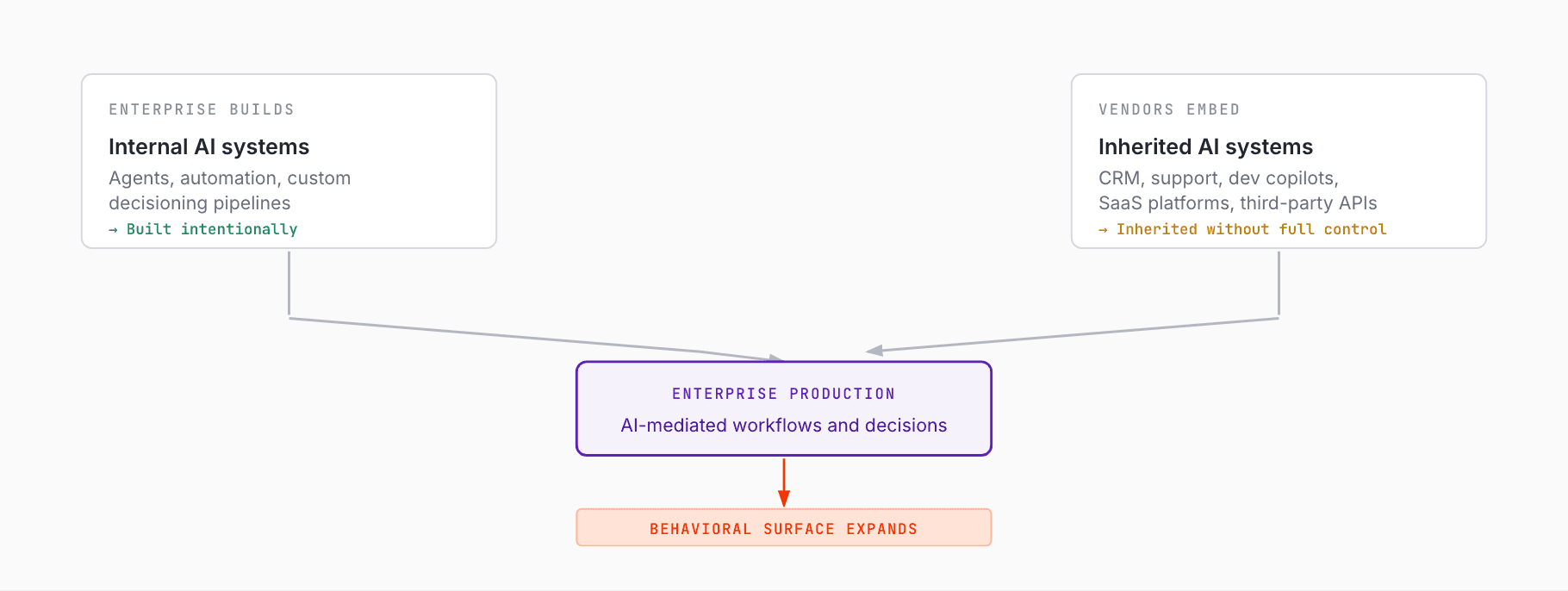
AI systems are already delivering real value: faster workflows, lower operational cost, more automation, better responsiveness, broader coverage. But deployment velocity is outrunning governance velocity. Product teams, platform teams, and vendors are introducing AI into production environments faster than most organizations can reason about how to monitor, constrain, and improve that behavior over time.
For many enterprises, AI is no longer something they are just building—it is something they are inheriting.
And inheriting AI means inheriting behavior you do not fully control.
That is the heart of the problem.
A New Class of Risk
As Enterprise AI systems become more autonomous—and more distributed across internal and external systems—the nature of risk changes fundamentally.
Traditional software systems are largely deterministic and bounded. Enterprise AI systems are increasingly probabilistic, adaptive, contextual, and open-ended. Their outputs are influenced not just by explicit logic, but by latent representations, dynamic prompting, multi-step tool use, prior state, changing models, orchestration decisions, and real-world ambiguity.
That shift introduces at least three structural properties that make Enterprise AI fundamentally harder to trust.

1. Behavior Is Non-Deterministic
The same input can produce different outputs across time, environment, model updates, orchestration changes, or contextual variation.
This is not just model drift in the abstract. It is behavioral drift and, in many enterprise settings, more specifically decision drift.
A system may be directionally useful and still not be trustworthy. It may be accurate enough on average and still fail in exactly the places where consistency matters most. Prior correctness does not guarantee future correctness. Testing does not guarantee consistency in production. Point-in-time evaluation does not guarantee stable behavior over time.
This matters because enterprises do not just need intelligent systems. They need reliable systems.
2. Execution Is Dynamic and Compositional
Agents do not just generate outputs. They plan. They chain. They call tools. They invoke other agents. They branch, retry, summarize, interpret, reframe, and choose between possible paths of execution.
The result is that the execution graph is no longer fixed.
Failures no longer live neatly inside one function, one endpoint, or one deterministic state transition. They are often distributed across steps. A small misunderstanding early in a workflow can compound later. A subtle classification error can propagate downstream. A mistaken tool call can alter context for later decisions. What looks like one bad output is often the surface expression of a multi-step behavioral failure.
This is different from debugging a single response.
It is different from evaluating a static prompt.
And it is very different from monitoring deterministic software execution.
3. Behavior, Not Access, Becomes the Primary Security Boundary
In traditional systems, the primary security question is often: who has access to what?
In Enterprise AI systems, that is still necessary—but increasingly insufficient.
The relevant questions become:
How is that access being used?
In what context is the system making a decision?
Is the output aligned with enterprise intent?
Is the system behaving correctly, not just permissibly?
This creates a new class of exposure. A system may have valid access and still behave unsafely. It may reveal the correct information to the wrong persona, at the wrong time, for the wrong purpose. It may take a technically allowed action that is operationally inappropriate. It may optimize toward the wrong objective while appearing superficially successful.
The failure, in these cases, is not in access control alone.
It is in behavioral control.
Across all of this, the deeper shift is simple:
We are moving from systems that execute logic
to systems that exhibit behavior.
And behavior cannot be governed well by static rules, threshold-based alerts, or post-hoc inspection alone.
It requires continuous runtime control.
Why Observability Isn’t Enough
Most of the tooling we have today was built for a different world.
Observability emerged for deterministic infrastructure and software systems. It assumes that systems emit logs, traces, and metrics that help engineers reconstruct what happened. It is excellent for understanding availability, latency, throughput, dependency health, service interactions, and operational incidents in traditional systems.
But Enterprise AI introduces a different challenge.
The problem is not just whether the system ran.
It is whether the system behaved correctly in context.
Whether it behaved consistently over time.
Whether a known mistake is likely to recur in a different form.
Whether the system can learn from failure instead of rediscovering it.
Those are not classic observability questions.
Observability Can See Activity, But Not Behavioral Correctness
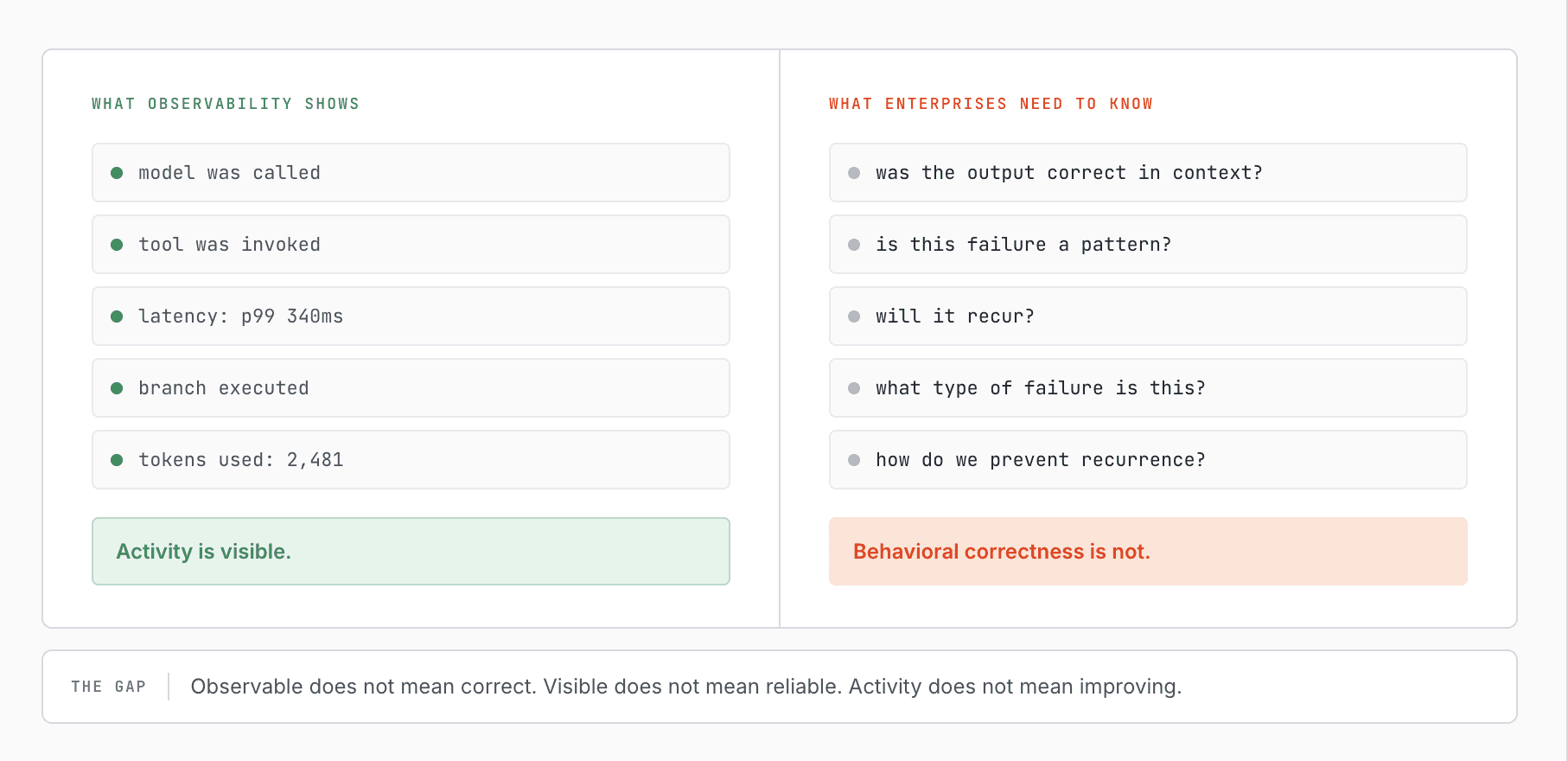
Observability platforms can capture events, traces, and tool chains. They can tell you that a model was called, that an agent used a tool, that a branch executed, or that a latency spike occurred.
But they struggle with what matters most in Enterprise AI:
Detecting semantic failures
Detecting behavioral failures
Determining whether an output was correct in context
Determining whether an action was aligned with intent
Recognizing when two superficially different failures are actually the same underlying pattern
Feeding structured insight back into the system so it can improve
At best, these tools show what happened.
They do not reliably determine whether the behavior was right or wrong. They do not classify the failure in a way that generalizes. They do not maintain an operational memory of what kind of mistake occurred and how it should be prevented next time. And they do not provide a native mechanism for turning observed failure into ongoing behavioral improvement.
That is why this is not just an observability gap.
It is a behavioral assurance gap.
The Core Unit of Failure Is Not an Incident—It Is a Pattern
Traditional systems often fail as isolated incidents. A broken deployment, a dependency outage, a misconfigured endpoint, a bad release. Root cause analysis can often isolate the issue, fix it, and move on.
Enterprise AI systems fail differently.
Their failures often repeat with variation. A misclassification here. A subtly similar misrouting there. A slightly different form of the same contextual misunderstanding in another workflow. The problem is not just one output. It is that the system keeps making variations of the same mistake.
This matters because systems cannot improve if every failure is treated as a one-off event.
What enterprises need is not just incident visibility. They need the ability to identify clusters of related behavioral failures, understand their shared structure, and carry that knowledge forward.
There Is No Native Failure Memory
Most tooling today stores events, responses, traces, and context.
But storing more raw context is not the same as storing useful behavioral intelligence.
A platform may retain transcripts, prompts, tool outputs, retrieval traces, or graph state and still fail to answer the critical questions:
What exactly was wrong?
Why was it wrong?
What type of failure was this?
What similar failures has the system made before?
What correction should apply the next time something like this occurs?
Without that layer, teams end up rediscovering the same classes of failures over and over again. Humans re-label similar mistakes manually. Remediations remain local instead of generalized. Systems accumulate data without accumulating operational learning.
Observable Does Not Mean Improving
Even when teams identify an issue, the loop often breaks.
Observability can alert. It can visualize. It can support investigation. It can help humans understand the path a system took.
But it does not, by itself:
Enable agents to receive structured feedback
Convert that feedback into reusable behavioral correction
Adjust inline controls to prevent recurrence
Adapt runtime guardrails based on emerging patterns
Feed corrections into model, policy, or workflow improvement loops
So the system may be visible—but it is not meaningfully getting better.
That is why “observable” is not the bar.
The real bar is:
Does the system learn from its failures and become more reliable over time?
For Enterprise AI, that requires more than observability.
It requires a new control layer.
The Case for Runtime Behavioral Assurance
What is missing is not another dashboard.
It is not simply better traces.
It is not a larger generic memory store.
What is missing is a layer that operates in the path of execution and is explicitly designed around behavior.
A layer that can:
Detect failures as they occur
Determine whether behavior is correct in context
Classify failures into meaningful patterns
Maintain memory of what went wrong and how to prevent it
Route structured human feedback when needed
Recommend or trigger remediation strategies
Improve future behavior in a continuous loop
That is what we mean by Runtime Behavioral Assurance.
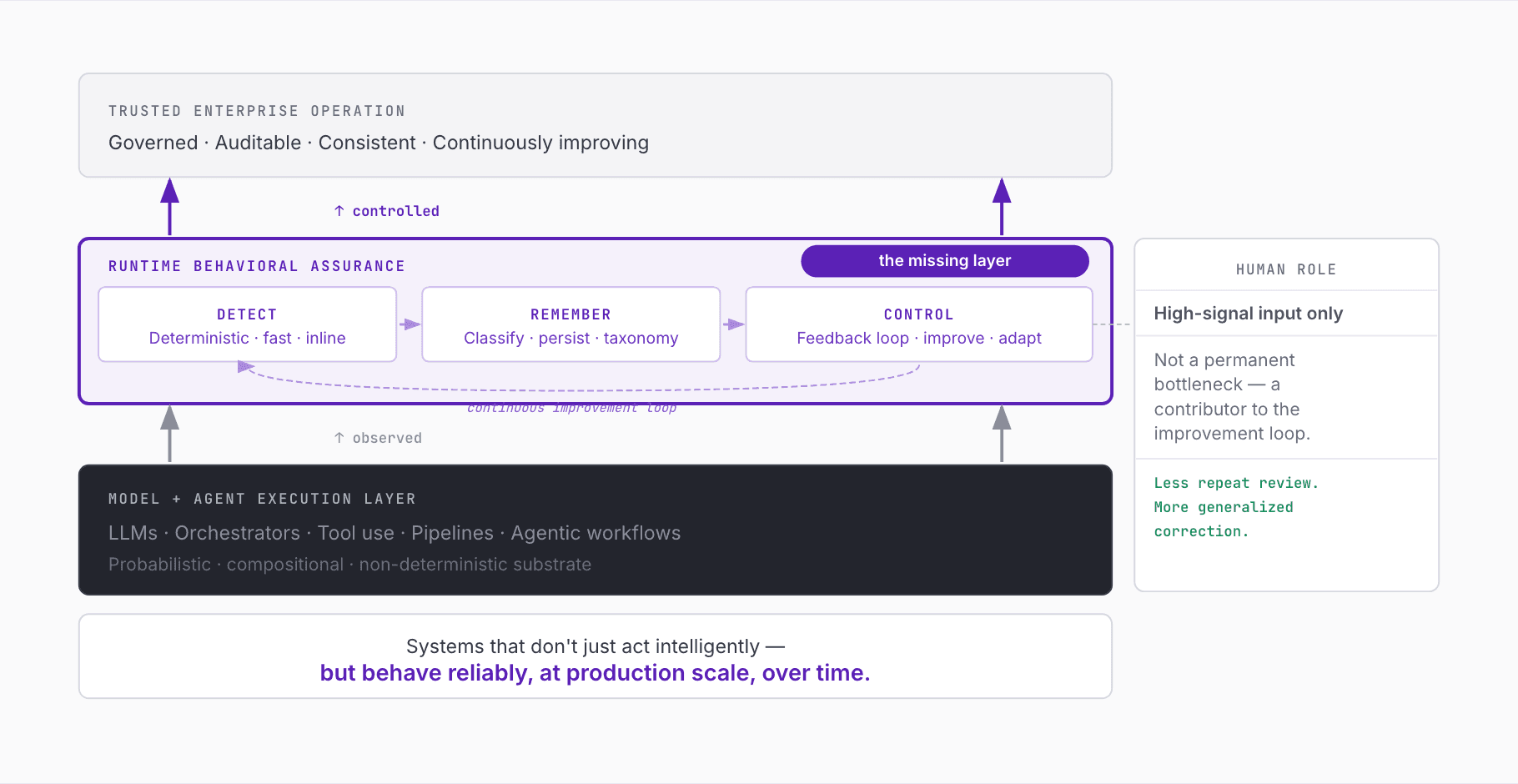
This layer sits between raw model capability and trusted enterprise operation.
It is not trying to replace models, orchestrators, or agents. It is not trying to replicate existing infrastructure tooling. It is the layer that ensures systems do not merely act intelligently, but behave reliably.
Runtime Behavioral Assurance is needed because the enterprise problem is not just “Can this model produce a good output?” It is:
Can this system behave correctly under real production conditions?
Can it remain consistent over time?
Can it detect when it is going wrong?
Can it remember what failure looks like?
Can it improve without requiring humans to manually supervise every edge case forever?
That is the platform need we are building toward.
What It Takes to Make This Real
Building runtime behavioral assurance is not one capability. It is a coordinated system. In practice, we think it requires at least three tightly connected primitives.
1. Deterministic Detection at Machine Speed
You cannot control what you cannot reliably detect.
The first requirement is the ability to identify behavioral failures and outliers inline and with low latency. This cannot depend purely on heavyweight offline analysis or human review after the fact. It must operate close enough to execution to matter.
This means detection has to be:
Fast
Predictable
Operationally reliable
Consistent in how it classifies behavior
Not everything in the AI stack can be deterministic. But the detection and classification of known behavioral failure patterns must be as stable and operationally dependable as possible.
This includes:
Detecting known classes of semantic and behavioral failure
Flagging novel outliers that do not fit prior patterns
Operating under latency constraints appropriate for runtime use
Producing outputs that are usable for control, not just analysis
This is one reason we believe lightweight models and targeted detection paths matter. Enterprises need a fast path for spotting failure, not just an expensive after-the-fact explanation layer.
2. Persistent Failure Intelligence
Detection alone is not enough.
A good runtime system does not just observe a failure. It turns that failure into durable operational knowledge.
Every significant failure should contribute to a system of record for behavior:
the relevant context
the failure type
the conditions under which it occurred
the downstream impact
how similar it is to prior failures
what remediation or correction is appropriate
This is where a failure taxonomy becomes essential.
Enterprises do not need an unbounded pile of examples. They need a structured way to normalize and reason about behavior. A taxonomy helps turn apparently chaotic mistakes into recognizable classes of failure. It enables aggregation, comparison, prioritization, triage, and consistent remediation. It makes behavioral reliability measurable.
This layer also has to function as a failure memory.
And that memory has to be more precise than a generic archive of prior state.
The system has to retain the essence of failure:
what went wrong
why it was wrong
what signals distinguished it
what should happen next time
That is what enables systems to learn across time rather than repeatedly rediscovering the same classes of error.
3. Closed-Loop Behavioral Control
Detection plus memory still does not solve the enterprise problem unless the system can change behavior.
This is the third primitive: a closed-loop control layer that can translate observed failure into improved future performance.
That loop can include:
Structured human input where it adds the most value
Recommendations for remediation strategies
Inline intervention when a failure can be prevented before it lands
Dynamic adjustment of runtime guardrails and policy boundaries
Routing of insights into prompt updates, workflow changes, policy logic, lightweight adaptation, supervised fine-tuning, or reinforcement-based learning loops
This matters because not every failure should be handled the same way.
Some require direct inline blocking or routing.
Some require a local workflow adjustment.
Some require new guardrails.
Some require additional human judgment.
Some should feed broader model or policy improvement mechanisms.
A real behavioral assurance layer has to support this spectrum.
And critically, it has to enable agents and systems to receive feedback in a structured form they can actually use. Human judgment remains important. But humans cannot be the permanent executor of every correction. Their role should increasingly be to provide high-signal input that the system can generalize and apply consistently.
The goal is not more review.
The goal is less repeat review for the same class of mistake.
That is what makes the loop closed.
Why This Is Not a Generic Context Graph Problem
A lot of new AI infrastructure is converging on some version of “memory,” “state,” or “context graph.” That direction makes sense up to a point: richer history and state can improve continuity. But we do not believe the enterprise reliability problem is solved by simply storing more context.
In practice, generic context graphs often become:
Bloated
Noisy
Expensive to maintain
Difficult to interpret
Weak at distinguishing high-signal failure information from irrelevant detail
They accumulate interaction history, execution traces, tool calls, and prior context. But without a principled way to extract the most relevant behavioral signal, they risk becoming large stores of partially useful state rather than a system that makes AI more reliable.
The problem is not “How do we retain everything?”
The problem is “How do we retain what is most useful for making future behavior more trustworthy?”
That is why we think the right unit is not generic memory.
It is failure intelligence.
What matters is not just that something happened before. What matters is whether the system knows:
what kind of failure it was
why it matters
how it relates to other failures
what remediation should apply
how to prevent recurrence
We are not trying to build a giant undifferentiated memory layer.
We are trying to build a system that captures the behaviorally relevant essence needed to make AI systems more performant, more reliable, and more governable.
What Comes Next
We believe a new layer is emerging in the Enterprise AI stack.
Just as cloud infrastructure gave rise to observability, security controls, and runtime policy enforcement, Enterprise AI will require its own foundational control systems. As agents become more capable, more embedded, and more autonomous, the need for:
behavioral control
runtime assurance
failure intelligence
human-guided improvement
continuous learning from production behavior
will only become more central.
This is not a niche requirement for frontier labs. It is a practical requirement for enterprises that want AI to move from promising to dependable.
The next phase of Enterprise AI will not just be about more capability. It will be about whether organizations can create systems that improve, govern, and contain that capability in production.
That is why we believe runtime behavioral assurance becomes foundational.
Why I’m Excited
This is one of the rare moments where a new technological shift creates space for a genuinely new platform layer.
We are already seeing early traction with teams deploying AI in production, and growing recognition across the broader ecosystem that runtime oversight, agent governance, and behavioral reliability are becoming central operational issues. Industry groups like TAG and analyst perspectives from Gartner are representative of a broader signal: the market is beginning to recognize that it is not enough to build AI systems that are capable. We need systems that are operationally trustworthy.
What feels especially exciting to me is that this problem sits at the intersection of several things that matter deeply:
real production pain
a genuine platform gap
a new control problem that existing tooling does not fully address
and the chance to help enterprises make AI not just more powerful, but more reliable
At ChatSee, we are building toward a world where:
AI systems are not just visible, but governable
failures are not just observed, but remembered and learned from
humans do not remain permanent bottlenecks, but become high-signal contributors to continuous system improvement
and enterprises can trust AI systems not because they never fail, but because failures become increasingly detectable, controllable, and non-recurring
If you are building or deploying AI systems in production, I would genuinely love to exchange notes.
You can reach me directly—or grab time here: sekhar@chatsee.ai